Note
Go to the end to download the full example code.
Classify fNIRS data with block diagonal matrices for HbO and HbR¶
This example demonstrates how to classify functional near-infrared spectroscopy
(fNIRS) data using block diagonal matrices for oxyhemoglobin (HbO) and
deoxyhemoglobin (HbR) signals, utilizing the HybridBlocks estimator.
This estimator computes block kernel or covariance matrices for each block of
channels, enabling separate processing of HbO and HbR signals.
Riemannian geometry methods generally already perform exceptionally well
for the classification of fNIRS data [1]. The HybridBlocks estimator
builds upon this strength by allowing for even finer control and tuning of
block-specific properties, which may further enhance classification accuracy.
We can then apply shrinkage independently to each block for
optimal performance [1]. Proof-of-principle work also shows sensitive and
specific fNIRS-based awareness detection using related methodology [2].
# Author: Tim Näher
import os
from urllib.request import urlretrieve
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.linalg import block_diag
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.compose import ColumnTransformer
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.pipeline import Pipeline, make_pipeline
from pyriemann.classification import SVC
from pyriemann.estimation import (
BlockCovariances,
Covariances,
Kernels,
Shrinkage,
ker_est_functions,
)
from pyriemann.utils.covariance import cov_est_functions
from pyriemann.utils._logging import logger
Parameters¶
block_size = 62 # Size of each block (number of channels for HbO and HbR)
n_jobs = -1 # Use all available cores
cv_splits = 5 # Number of cross-validation folds
random_state = 42 # Random state for reproducibility
Define the HybridBlocks estimator and helper transformers¶
class Stacker(TransformerMixin, BaseEstimator):
"""Stacks values of a DataFrame column into a 3D array."""
def fit(self, X, y=None):
self._is_fitted = True
return self
def transform(self, X):
assert isinstance(X, pd.DataFrame), "Input must be a DataFrame"
assert X.shape[1] == 1, "DataFrame must have only one column"
return np.stack(X.iloc[:, 0].values)
def __sklearn_is_fitted__(self):
return hasattr(self, "_is_fitted") and self._is_fitted
class FlattenTransformer(TransformerMixin, BaseEstimator):
"""Flattens the last two dimensions of an array.
ColumnTransformer requires 2D output, so this transformer is needed
"""
def fit(self, X, y=None):
self._is_fitted = True
return self
def transform(self, X):
return X.reshape(X.shape[0], -1)
def __sklearn_is_fitted__(self):
return hasattr(self, "_is_fitted") and self._is_fitted
class HybridBlocks(TransformerMixin, BaseEstimator):
"""Estimation of block kernel or covariance matrices.
Perform block matrix estimation for each given time series,
computing either kernel matrices or covariance matrices for
each block based on the specified metrics. The block matrices
are then concatenated to form the final block diagonal matrices.
It is possible to add different shrinkage values for each block.
This estimator is helpful when dealing with data from multiple
sources or modalities (e.g. fNIRS, EMG, EEG, gyro, acceleration),
where each block corresponds to a different source or modality
and benefits from separate processing and tuning.
Parameters
----------
block_size : int | list of int
Sizes of individual blocks given as int for same-size blocks,
or list for varying block sizes.
metric : string | list of string, default="linear"
Parameter(s) to estimate kernel or covariance matrices.
For kernel matrices, supported metrics are those from
``Kernels``: "linear", "poly", "polynomial", "rbf", "laplacian",
"cosine", etc.
For covariance matrices, supported estimators are those from
``Covariances``: "scm", "lwf", "oas", "mcd", etc.
If a list is provided, it must match the number of blocks.
shrinkage : float | list of float, default=0
Shrinkage parameter(s) to regularize each block's matrix.
If a single float is provided, it is applied to all blocks.
If a list is provided, it must match the number of blocks.
n_jobs : int, default=None
Number of jobs to use for the computation.
**kwargs : dict
Any further parameters are passed directly to the kernel function(s)
or covariance estimator(s).
See Also
--------
BlockCovariances
"""
def __init__(
self,
block_size,
metric="linear",
shrinkage=0,
n_jobs=None,
**kwargs,
):
self.block_size = block_size
self.metric = metric
self.shrinkage = shrinkage
self.n_jobs = n_jobs
self.kwargs = kwargs
def fit(self, X, y=None):
"""Fit.
Prepare per-block transformers.
Parameters
----------
X : ndarray, shape (n_matrices, n_channels, n_times)
Multi-channel time series.
y : None
Not used, here for compatibility with scikit-learn API.
Returns
-------
self : HybridBlocks instance
The HybridBlocks instance.
"""
n_matrices, n_channels, n_times = X.shape
# Determine block sizes
if isinstance(self.block_size, int):
n_blocks_ = n_channels // self.block_size
self._block_sizes = [self.block_size] * n_blocks_
remainder = n_channels % self.block_size
if remainder > 0:
self._block_sizes.append(remainder)
elif isinstance(self.block_size, list):
self._block_sizes = self.block_size
if sum(self._block_sizes) != n_channels:
raise ValueError(
"Sum of block sizes must equal number of channels"
)
else:
raise ValueError("block_size must be int or list of ints")
n_blocks = len(self._block_sizes)
# Compute block indices
self._block_indices = []
start = 0
for size in self._block_sizes:
end = start + size
self._block_indices.append((start, end))
start = end
# Handle metric parameter
if isinstance(self.metric, str):
metrics = [self.metric] * n_blocks
elif isinstance(self.metric, list):
if len(self.metric) != n_blocks:
raise ValueError(
f"Length of metric list ({len(self.metric)}) "
f"must match number of blocks ({n_blocks})"
)
metrics = self.metric
else:
raise ValueError(
"Parameter 'metric' must be a string or a list of strings."
)
# Handle shrinkage parameter
if isinstance(self.shrinkage, (float, int)):
shrinkages = [self.shrinkage] * n_blocks
elif isinstance(self.shrinkage, list):
if len(self.shrinkage) != n_blocks:
raise ValueError(
f"Length of shrinkage list ({len(self.shrinkage)}) "
f"must match number of blocks ({n_blocks})"
)
shrinkages = self.shrinkage
else:
raise ValueError(
"Parameter 'shrinkage' must be a float or a list of floats."
)
# Build per-block pipelines
self._block_names = [f"block_{i}" for i in range(n_blocks)]
transformers = []
for i, (indices, metric, shrinkage, block_name) in enumerate(
zip(self._block_indices, metrics, shrinkages, self._block_names)
):
# Build the pipeline for this block
block_pipeline = make_pipeline(Stacker())
# Add kernel or covariance estimator depending on metric param
if metric in ker_est_functions:
name = "kernels"
estimator = Kernels(
metric=metric,
n_jobs=self.n_jobs,
**self.kwargs
)
elif metric in cov_est_functions.keys():
name = "covariances"
estimator = Covariances(estimator=metric, **self.kwargs)
else:
raise ValueError(
f"Metric '{metric}' is not recognized as a kernel metric "
"or a covariance estimator."
)
block_pipeline.steps.append((name, estimator))
# Add shrinkage if provided
# TODO: add support for different shrinkage types at some point?
if shrinkage != 0:
block_pipeline.steps.append(
("shrinkage", Shrinkage(shrinkage=shrinkage))
)
# Add the flattening transformer at the end of the pipeline
block_pipeline.steps.append(("flatten", FlattenTransformer()))
transformers.append((block_name, block_pipeline, [block_name]))
# create the column transformer with per-block pipelines
self.preprocessor_ = ColumnTransformer(transformers)
# Prepare the DataFrame
X_df = self._prepare_dataframe(X)
# Fit the preprocessor
self.preprocessor_.fit(X_df)
return self
def transform(self, X):
"""Estimate block kernel or covariance matrices.
Parameters
----------
X : ndarray, shape (n_matrices, n_channels, n_times)
Multi-channel time series.
Returns
-------
X_new : ndarray, shape (n_matrices, n_channels, n_channels)
Block diagonal matrices, kernel or covariance matrices.
"""
# make the df wheren each block is 1 column
X_df = self._prepare_dataframe(X)
# Transform the data
transformed_blocks = []
data_transformed = self.preprocessor_.transform(X_df)
# calculate the number of features per block
features_per_block = [size * size for size in self._block_sizes]
# compute the indices where to split the data
split_indices = np.cumsum(features_per_block)[:-1]
# split the data into flattened blocks
blocks_flat = np.split(data_transformed, split_indices, axis=1)
# reshape each block back to its original shape
for i, block_flat in enumerate(blocks_flat):
size = self._block_sizes[i]
block = block_flat.reshape(-1, size, size)
transformed_blocks.append(block)
# Construct the block diagonal matrices
X_new = np.array([
block_diag(*[Xt[i] for Xt in transformed_blocks])
for i in range(X.shape[0])
])
return X_new
def _prepare_dataframe(self, X):
"""Converts the data into a df with each block as column."""
data_dict = {}
for i, (start, end) in enumerate(self._block_indices):
data_dict[self._block_names[i]] = list(X[:, start:end, :])
return pd.DataFrame(data_dict)
def download_fnirs(data_path):
"""Download the dataset.
Parameters
----------
data_path : str
Path to the destination folder for data download.
"""
filenames = ["X", "y"]
if not os.path.exists(data_path):
os.makedirs(data_path, exist_ok=True)
logger.info("\n")
for filename in filenames:
src = f"https://zenodo.org/records/13841869/files/{filename}.npy"
dst = os.path.join(data_path, f"{filename}.npy")
if not os.path.exists(dst):
msg = f"Downloading file '{filename}' from '{src}' to '{dst}'."
logger.info(msg)
urlretrieve(src, dst)
Download example data and plot¶
data_path = "./data"
download_fnirs(data_path)
X = np.load(os.path.join(data_path, "X.npy"))
y = np.load(os.path.join(data_path, "y.npy"))
print(
f"Data loaded: {X.shape[0]} trials, {X.shape[1]} channels, "
f"{X.shape[2]} time points"
)
# Get trials with the label "OP" for "Own Paradigm"
MT_label = "OP"
MT_trials_indices = np.where(y == MT_label)[0]
# Average the data across the "OP" trials
X_MT_erp = np.mean(X[MT_trials_indices, :, :], axis=0)
# select example channel
channel_index = 2
# Plot the averaged signals
plt.figure(figsize=(10, 5))
plt.plot(X_MT_erp[channel_index, :], label="HbO", color="red")
plt.plot(X_MT_erp[channel_index + 62, :], label="HbR", color="blue")
plt.xlabel("Time samples")
plt.ylabel("Signal Amplitude")
plt.title(f"ERP for OP [Own Paradigm] trials in channel {channel_index}")
plt.legend()
plt.show()
![ERP for OP [Own Paradigm] trials in channel 2](../../_images/sphx_glr_plot_classif_fnirs_001.png)
Data loaded: 96 trials, 124 channels, 36 time points
Set up the pipelines¶
# Define the pipeline with HybridBlocks and SVC classifier
pipeline_hybrid_blocks = Pipeline(
[
("block_kernels", HybridBlocks(
block_size=block_size,
metric=["cov", "rbf"],
shrinkage=[0.01, 0],
)),
("classifier", SVC(metric="riemann", C=0.1)),
]
)
# Define the pipeline with BlockCovariances and SVC classifier
pipeline_blockcovariances = Pipeline(
[
("covariances", BlockCovariances(
block_size=block_size,
estimator="lwf",
shrinkage=0.01,
)),
("classifier", SVC(metric="riemann", C=0.1)),
]
)
# Define cross-validation
cv = StratifiedKFold(
n_splits=cv_splits,
random_state=random_state,
shuffle=True
)
Fit the pipelines¶
cv_scores_hybrid_blocks = cross_val_score(
pipeline_hybrid_blocks, X, y,
cv=cv, scoring="accuracy", n_jobs=n_jobs
)
cv_scores_blockcovariances = cross_val_score(
pipeline_blockcovariances, X, y,
cv=cv, scoring="accuracy", n_jobs=n_jobs
)
Print and plot results¶
acc_hybrid_blocks = np.mean(cv_scores_hybrid_blocks)
acc_blockcovariances = np.mean(cv_scores_blockcovariances)
print(f"Mean accuracy for HybridBlocks: {acc_hybrid_blocks:.2f}")
print(f"Mean accuracy for BlockCovariances: {acc_blockcovariances:.2f}")
# plot a scatter plot of CV and scores
plt.figure(figsize=(6, 6))
plt.scatter(cv_scores_hybrid_blocks, cv_scores_blockcovariances)
plt.plot([0.4, 1], [0.4, 1], "--", color="black")
plt.xlabel("Accuracy HybridBlocks")
plt.ylabel("Accuracy BlockCovariances")
plt.title("Comparison of HybridBlocks and Covariances")
plt.legend(["CV Fold Scores"])
plt.show()
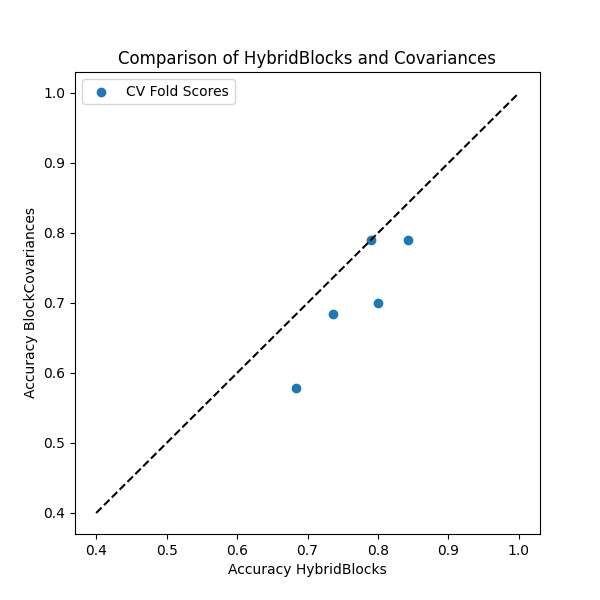
Mean accuracy for HybridBlocks: 0.77
Mean accuracy for BlockCovariances: 0.71
Conclusion¶
The HybridBlocks estimator allows us to use the best combination of
metrics and shrinkage values for our fNIRS classification of mental imagery.
By using block diagonal matrices for HbO and HbR signals, we can tune our
classifier to HbO and HbR signals separately, which can improve
classification performance, since fNIRS classification methods are often
lacking in this regard. Since there are few data available in this example,
we just calculate cross validation scores. This means that the classification
accuracies will be overestimated. If more data per class are available
one should use a train-test split to get a more realistic estimate of the
absolute classification performance.
References¶
Total running time of the script: (0 minutes 17.964 seconds)