Note
Go to the end to download the full example code.
Comparison of pipelines for transfer learning¶
We compare the classification performance of MDM on different strategies for transfer learning.
Matrices are simulated from a toy model based on the Riemannian Gaussian distribution and the differences in statistics between source and target distributions are determined by a set of parameters that have control over the distance between the centers of each dataset, the angle of rotation between the means of each class, and the differences in dispersion of the matrices from each dataset.
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.pipeline import make_pipeline
from pyriemann.classification import MDM
from pyriemann.datasets.simulated import make_classification_transfer
from pyriemann.tangentspace import TangentSpace
from pyriemann.transfer import (
TLSplitter,
TLDummy,
TLCenter,
TLScale,
TLRotate,
TLClassifier,
MDWM,
)
Pipelines¶
We consider several pipelines for transfer learning:
calib: use only data from target-train partition, classifier is trained only with matrices from the target domain.
dummy: no transfer learning at all, ie no transformation of data between domains, classifier is trained only with matrices from the source domain.
rct: recenter data from each domain to the identity matrix [1], classifier is trained only with matrices from the source domain.
rpa: match the statistical distributions in a semi-supervised way with Riemannian Procrustes Analysis (RPA) [2]: center, stretch and rotate matrices in manifold. Classifier is trained with matrices from source and target.
mdwm: improve the MDM classifier with a weighting strategy, giving the minimum distance to weighted mean (MDWM) [3].
tsa: align tangent vectors by Procrustes analysis [4]: center, normalize and rotate vectors in tangent space.
methods = ["calib", "dummy", "rct", "rpa", "mdwm", "tsa"]
scores = {meth: [] for meth in methods}
# Base classifier to consider in manifold
clf_base = MDM()
# Choose seed for reproducible results
seed = 100
# Create a dataset with two domains, each with two classes both datasets
# are generated by the same generative procedure with the SPD Gaussian
# and one of them is transformed by a matrix A, i.e. X <- A @ X @ A.T
X_enc, y_enc = make_classification_transfer(
n_matrices=100,
class_sep=0.75,
class_disp=1.0,
domain_sep=5.0,
theta=3*np.pi/5,
random_state=seed,
)
# Object for splitting the datasets into training and validation partitions
# the training set is composed of all matrices from the source domain
# plus a partition of the target domain whose size we can control
target_domain = "target_domain"
n_splits = 5 # how many times to split the target domain into train/test
tl_cv = TLSplitter(
target_domain=target_domain,
cv=StratifiedShuffleSplit(n_splits=n_splits, random_state=seed),
)
# Vary the proportion of the target domain for training
target_train_frac_array = np.linspace(0.01, 0.20, 10)
for target_train_frac in tqdm(target_train_frac_array):
# Change fraction of the target training partition
tl_cv.cv.train_size = target_train_frac
# Create dict for storing results of this particular CV split
scores_cv = {meth: [] for meth in scores.keys()}
# Carry out the cross-validation
for train_idx, test_idx in tl_cv.split(X_enc, y_enc):
# Split the dataset into training and testing
X_enc_train, X_enc_test = X_enc[train_idx], X_enc[test_idx]
y_enc_train, y_enc_test = y_enc[train_idx], y_enc[test_idx]
# Calibration
pipeline = make_pipeline(
TLClassifier(
target_domain=target_domain,
estimator=clf_base,
domain_weight={"source_domain": 0.0, "target_domain": 1.0},
),
)
pipeline.fit(X_enc_train, y_enc_train)
scores_cv["calib"].append(pipeline.score(X_enc_test, y_enc_test))
# Dummy
pipeline = make_pipeline(
TLDummy(),
TLClassifier(
target_domain=target_domain,
estimator=clf_base,
domain_weight={"source_domain": 1.0, "target_domain": 0.0},
),
)
pipeline.fit(X_enc_train, y_enc_train)
scores_cv["dummy"].append(pipeline.score(X_enc_test, y_enc_test))
# Recentering pipeline
pipeline = make_pipeline(
TLCenter(target_domain=target_domain),
TLClassifier(
target_domain=target_domain,
estimator=clf_base,
domain_weight={"source_domain": 1.0, "target_domain": 0.0},
),
)
pipeline.fit(X_enc_train, y_enc_train)
scores_cv["rct"].append(pipeline.score(X_enc_test, y_enc_test))
# RPA pipeline
pipeline = make_pipeline(
TLCenter(target_domain=target_domain),
TLScale(
target_domain=target_domain,
final_dispersion=1,
centered_data=True,
),
TLRotate(target_domain=target_domain, metric="euclid"),
TLClassifier(
target_domain=target_domain,
estimator=clf_base,
domain_weight={"source_domain": 0.5, "target_domain": 0.5},
),
)
pipeline.fit(X_enc_train, y_enc_train)
scores_cv["rpa"].append(pipeline.score(X_enc_test, y_enc_test))
# MDWM pipeline
domain_tradeoff = 1 - np.exp(-100 * target_train_frac)
pipeline = MDWM(
domain_tradeoff=domain_tradeoff,
target_domain=target_domain,
metric="riemann",
)
pipeline.fit(X_enc_train, y_enc_train)
scores_cv["mdwm"].append(pipeline.score(X_enc_test, y_enc_test))
# TSA pipeline
pipeline = make_pipeline(
TangentSpace(metric="riemann"),
TLCenter(target_domain=target_domain),
TLScale(target_domain=target_domain),
TLRotate(target_domain=target_domain),
TLClassifier(
target_domain=target_domain,
estimator=LogisticRegression(),
domain_weight={"source_domain": 0.5, "target_domain": 0.5},
),
)
pipeline.fit(X_enc_train, y_enc_train)
scores_cv["tsa"].append(pipeline.score(X_enc_test, y_enc_test))
# Get the average score of each pipeline
for meth in scores.keys():
scores[meth].append(np.mean(scores_cv[meth]))
# Store the results for each method on this particular seed
for meth in scores.keys():
scores[meth] = np.array(scores[meth])
0%| | 0/10 [00:00<?, ?it/s]/home/docs/checkouts/readthedocs.org/user_builds/pyriemann/checkouts/latest/pyriemann/transfer/_estimators.py:754: UserWarning: Not enough vectors for target domain
warnings.warn("Not enough vectors for target domain")
/home/docs/checkouts/readthedocs.org/user_builds/pyriemann/checkouts/latest/pyriemann/transfer/_estimators.py:754: UserWarning: Not enough vectors for target domain
warnings.warn("Not enough vectors for target domain")
/home/docs/checkouts/readthedocs.org/user_builds/pyriemann/checkouts/latest/pyriemann/transfer/_estimators.py:754: UserWarning: Not enough vectors for target domain
warnings.warn("Not enough vectors for target domain")
/home/docs/checkouts/readthedocs.org/user_builds/pyriemann/checkouts/latest/pyriemann/transfer/_estimators.py:754: UserWarning: Not enough vectors for target domain
warnings.warn("Not enough vectors for target domain")
/home/docs/checkouts/readthedocs.org/user_builds/pyriemann/checkouts/latest/pyriemann/transfer/_estimators.py:754: UserWarning: Not enough vectors for target domain
warnings.warn("Not enough vectors for target domain")
10%|█ | 1/10 [00:00<00:03, 2.26it/s]
20%|██ | 2/10 [00:01<00:04, 1.79it/s]
30%|███ | 3/10 [00:01<00:04, 1.67it/s]
40%|████ | 4/10 [00:02<00:03, 1.68it/s]
50%|█████ | 5/10 [00:02<00:02, 1.69it/s]
60%|██████ | 6/10 [00:03<00:02, 1.71it/s]
70%|███████ | 7/10 [00:04<00:01, 1.73it/s]
80%|████████ | 8/10 [00:04<00:01, 1.75it/s]
90%|█████████ | 9/10 [00:05<00:00, 1.73it/s]
100%|██████████| 10/10 [00:05<00:00, 1.70it/s]
100%|██████████| 10/10 [00:05<00:00, 1.72it/s]
Results¶
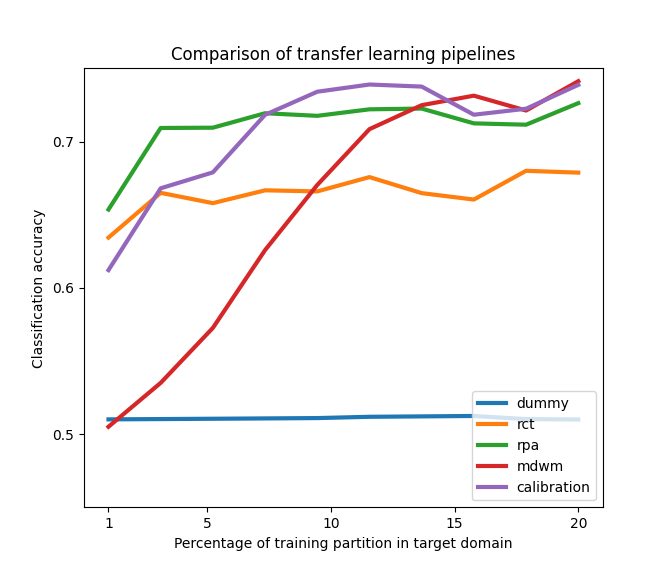
Plot the results, reproducing Figure 2 of [2].
fig, ax = plt.subplots(figsize=(6.7, 5.7))
for meth in scores.keys():
ax.plot(
target_train_frac_array,
scores[meth],
label=meth,
lw=3.0 if meth == "calib" else 2.0,
)
ax.legend(loc="lower right")
ax.set_ylim(0.5, 0.75)
ax.set_yticks([0.5, 0.6, 0.7])
ax.set_xlim(0.00, 0.21)
ax.set_xticks([0.01, 0.05, 0.10, 0.15, 0.20])
ax.set_xticklabels([1, 5, 10, 15, 20])
ax.set_xlabel("Percentage of training partition in target domain")
ax.set_ylabel("Classification accuracy")
ax.set_title("Comparison of transfer learning pipelines")
plt.show()
References¶
Total running time of the script: (0 minutes 6.452 seconds)