pyriemann.classification.MDM¶
- class pyriemann.classification.MDM(metric='riemann', n_jobs=1)[source]¶
Classification by Minimum Distance to Mean.
For each of the given classes \(k = 1, \ldots, K\), a centroid \(\mathbf{M}^k\) is estimated according to the chosen metric.
Then, for each new SPD/HPD matrix \(\mathbf{X}\), the class is affected according to the nearest centroid [1]:
\[\hat{k} = \arg \min_{k} d (\mathbf{X}, \mathbf{M}^k)\]- Parameters:
- metricstring | dict, default=”riemann”
Metric used for mean estimation (for the list of supported metrics, see
pyriemann.geometry.mean.gmean()) and for distance estimation (seepyriemann.geometry.distance.distance()). The metric can be a dict with two keys, “mean” and “distance” in order to pass different metrics. Typical usecase is to pass “logeuclid” metric for the “mean” in order to boost the computional speed, and “riemann” for the “distance” in order to keep the good sensitivity for the classification.- n_jobsint, default=1
Number of jobs to use for the computation. This works by computing each of the class centroid in parallel. If -1 all CPUs are used. If 1 is given, no parallel computing code is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used. Thus for n_jobs = -2, all CPUs but one are used.
- Attributes:
- classes_ndarray, shape (n_classes,)
Labels for each class.
- covmeans_ndarray, shape (n_classes, n_channels, n_channels)
Centroids for each class.
See also
KmeansFgMDMKNearestNeighbor
References
[1]Multiclass Brain-Computer Interface Classification by Riemannian Geometry A. Barachant, S. Bonnet, M. Congedo, and C. Jutten. IEEE Transactions on Biomedical Engineering, vol. 59, no. 4, p. 920-928, 2012.
[2]Riemannian geometry applied to BCI classification A. Barachant, S. Bonnet, M. Congedo and C. Jutten. 9th International Conference Latent Variable Analysis and Signal Separation (LVA/ICA 2010), LNCS vol. 6365, 2010, p. 629-636.
- fit(X, y, sample_weight=None)[source]¶
Fit (estimates) the centroids.
- Parameters:
- Xndarray, shape (n_matrices, n_channels, n_channels)
Set of SPD/HPD matrices.
- yndarray, shape (n_matrices,)
Labels for each matrix.
- sample_weightNone | ndarray, shape (n_matrices,), default=None
Weights for each matrix. If None, it uses equal weights.
- Returns:
- selfMDM instance
The MDM instance.
- fit_transform(X, y=None, sample_weight=None)¶
Fit and transform in a single function.
- Parameters:
- Xndarray, shape (n_matrices, n_channels, n_channels)
Set of SPD matrices.
- yNone | ndarray, shape (n_matrices,), default=None
Labels for each matrix.
- sample_weightNone | ndarray, shape (n_matrices,), default=None
Weights for each matrix. If None, it uses equal weights.
- Returns:
- distndarray, shape (n_matrices, n_centroids)
Distance to each centroid.
- get_metadata_routing()¶
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)¶
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- predict(X)[source]¶
Get the predictions.
- Parameters:
- Xndarray, shape (n_matrices, n_channels, n_channels)
Set of SPD/HPD matrices.
- Returns:
- predndarray of int, shape (n_matrices,)
Predictions for each matrix according to the nearest centroid.
- predict_proba(X)[source]¶
Predict proba using softmax of negative squared distances.
- Parameters:
- Xndarray, shape (n_matrices, n_channels, n_channels)
Set of SPD/HPD matrices.
- Returns:
- probndarray, shape (n_matrices, n_classes)
Probabilities for each class.
- score(X, y, sample_weight=None)¶
Return the mean accuracy on the given test data and labels.
- Parameters:
- Xndarray, shape (n_matrices, n_channels, n_channels)
Test set of SPD matrices.
- yndarray, shape (n_matrices,)
True labels for each matrix.
- sample_weightNone | ndarray, shape (n_matrices,), default=None
Weights for each matrix.
- Returns:
- scorefloat
Mean accuracy of clf.predict(X) wrt. y.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MDM¶
Configure whether metadata should be requested to be passed to the
fitmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter infit.
- Returns:
- selfobject
The updated object.
- set_output(*, transform=None)¶
Set output container.
Refer to the user guide for more details and Introducing the set_output API for an example on how to use the API.
- Parameters:
- transform{“default”, “pandas”, “polars”}, default=None
Configure output of transform and fit_transform.
“default”: Default output format of a transformer
“pandas”: DataFrame output
“polars”: Polars output
None: Transform configuration is unchanged
Added in version 1.4: “polars” option was added.
- Returns:
- selfestimator instance
Estimator instance.
- set_params(**params)¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MDM¶
Configure whether metadata should be requested to be passed to the
scoremethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.
Examples using pyriemann.classification.MDM¶
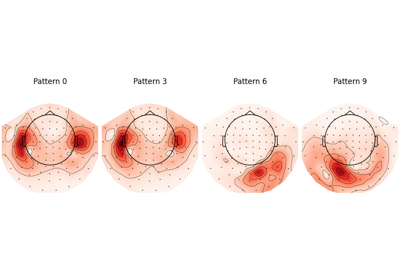
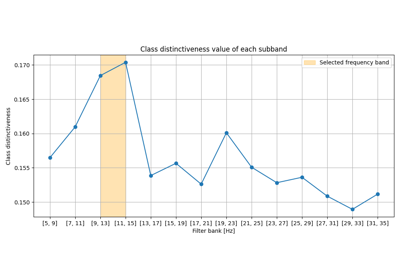
Frequency band selection on the manifold for motor imagery classification
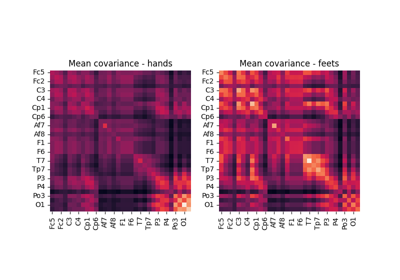
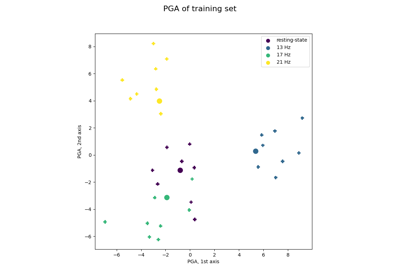
Visualization of SSVEP-based BCI Classification in Tangent Space
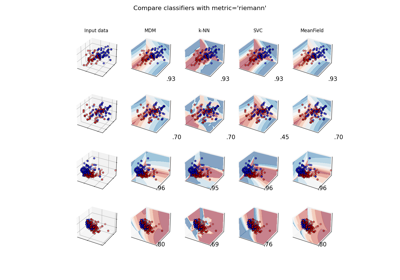
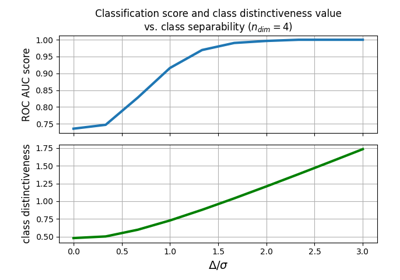
Classification accuracy vs class distinctiveness vs class separability